

 しらせ(HN)
しらせ(HN)





お疲れ様です。
しらせです。
最近マイブームはスプラトゥーン3です。
いろんな人の実況動画を見ていますが特に強い人のプレイは本当に参考になりますね。
そんな中ふと思ったのですが、これだけ多くのスプラトゥーン実況動画があるのだから、
「1つくらい俺が映ってる動画あるんじゃね?」
ただ、他人の動画の中に自分のアバターが映り込んでいる動画なんて探せなくね?
ということで何とかできないかと挑戦した記録です。
もくじ
やりたいこと
やりたいことはいたって簡単です。
「他の実況者のスプラトゥーンプレイ動画に自分が紛れていないか?」
を調べることです。
いまだにS+20台の私ですが、もしかしたら「た〇じ」さんや「テoラミス」さん「ぱい〇ぽ~」さんとかの動画に紛れていないか?!
めちゃくちゃ気になります。
動画を調べるのも大変だし、1つ1つ確認しながらというのもつらい。
何とか自動的に抽出できないか。
そこで考えました。
「Amazon Rekognitionを使ってみよう!」

確か顔認識やテキスト抽出があった気がしました。
ちょっと触ってみたかったこともあって試すことにしました。
やってみたいことは以下の流れです。
抽出の流れ
- Youtubeから対象のスプラ動画を抽出
- mp4形式の動画からフレーム単位の画像を抽出
- 画像データから自分の名前を検出
3ステップで簡単そうに見えますね。
この3番目をAmazon Rekognitionに頑張ってもらえないか?というところです。
ちなみにAmazon Rekognitionにおいてテキスト検出は、画像分析のグループ2に含まれ無料利用枠期間中は5,000枚/月まで使えます。
嬉しいですね。
でも最初の 1,000,000 ページについて画像あたり 0.0013USDって、1,000,000枚処理したら月間19万円ですよ。※$=150円の場合
たっか。
やってみた結果
まずは抽出の流れ(1)の「Youtubeから対象のスプラ動画を抽出」です。
1.Youtubeから対象のスプラ動画を抽出
適当にテストしたいだけなので手元のWindows環境にPythonをインストールして試すことにしました。
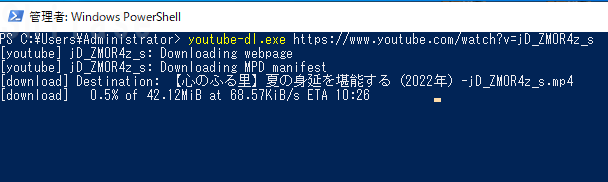
mp4形式で使えるといろいろ都合がいいので、手っ取り早くpipで「youtube-dl」を使ってみることにしました。
が、これがめちゃくちゃ遅いんですね。。
試しに私が公開している身延の動画をダウンロードすると、7分くらいの動画なのに10分近く掛かる見込みです。
(参考)【心のふる里】夏の身延を堪能する(2022年)
早速壁に当たったんですが、調べてみると同様のツールで「yt-dlp」というyoutube-dlからフォークされたツールがあることを知りました。
yt-dlp/yt-dlp - github.com
https://github.com/yt-dlp/yt-dlp/
こちらは速度制限が解除されている様子で同じ動画で試すと確かに早い!
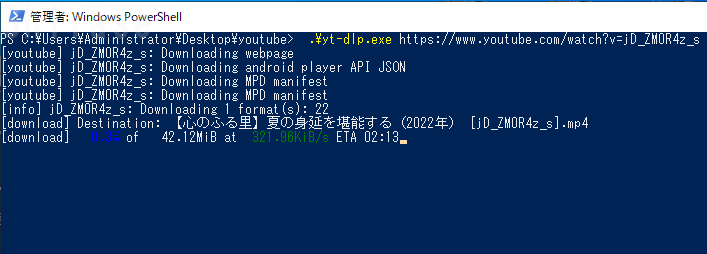
こちらは2分も経たずに数秒でダウンロードできました。
実行ファイルが単独で公開されているのでインストール作業も不要で便利です。
取得した動画はちゃんとmp4形式となっています。
2.mp4形式の動画からフレーム単位の画像を抽出
続いてAmazon Rekognitionに分析に掛ける前に画像データを用意する必要があります。
mp4データはそのままでは使えないので、動画から画像データに変換します。
以下のサイトを参考にさせていただき、pythonでpng形式に変換することにしました。
(参考)Pythonで動画から毎秒のフレームを抽出する|CO-WRITE - gri.jp
https://gri.jp/media/entry/4571
pythonのパッケージに追加で「opencv-python 4.6.0.66」をインストールしています。
試しにスプラ動画を画像にしてみると、うまくいってそうです。
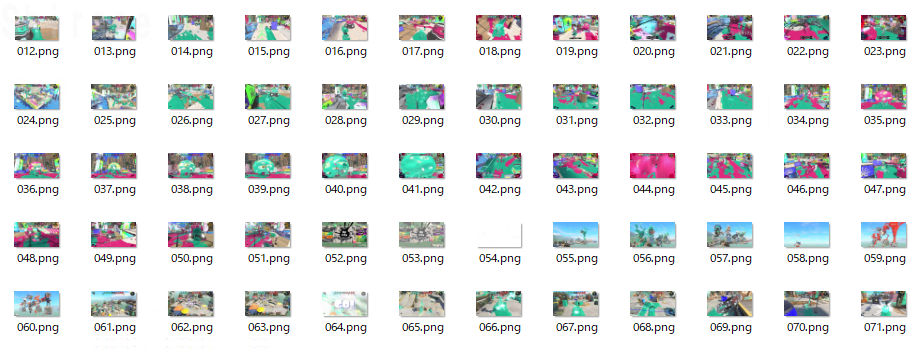
(前処理①)
私はここで気づきました。
「1秒1枚の画像だと10分動画で、、、600枚?!」
無料枠もあっという間に終わりますね。
ということで、分析が必要な画像だけに絞りたいので開始時のメンバー一覧画面だけを何とか抽出したくなりました。
↓このシーンです。

試合開始時に対戦者のニックネームやID、プレートやバッジが見える画面ですね。
このシーンで名前が抜き出せないか?と思って調べ始めました。
調べていくうちにオープンソースのOCRである「Tesseract-OCR」がApache License v2で使えそうなことがわかりました。
以下のサイトを参考にWindowsにインストールしました。
Tesseract OCR をWindowsにインストールする方法 - gammasoft.jp
https://gammasoft.jp/blog/tesseract-ocr-install-on-windows/
tesseract-ocr/tesseract - github.com
https://github.com/tesseract-ocr/tesseract
(ダウンロード)UB-Mannheim/tesseract - github.com
https://github.com/UB-Mannheim/tesseract/wiki
そして試しに手元の画像で試してみますが、、、
↓
全然だめですね。。
ワードとして識別されていない。。
スプラフォントはtesseractは対応していなそうだ。。
ただIDっぽい数字は取れているので数字が多い場合はメンバー一覧シーンとして考えてよさそうですね?
(前処理②)
tesseractで数値が多く含まれる場合にはメンバー一覧シーンととらえて候補にするスクリプトを入れ込みました。
今回ベースのスクリプトはPowerShellで、画像/動画処理系をpythonで動かしています。
tesseractで抽出したファイルでサイズが10Byte以上かつ、数字を8個以上含む場合にメンバー一覧シーン候補としました。
ここで試しに最近よく見ているダークネス山本さんの動画「【19キル】ヒト速ガン積みラピッドブラスターでしか出来ない技が強すぎて笑えないんだがwwww【スプラトゥーン3】」で動作をテストしてみます。
8分48秒の動画なのでcv2でそのまま抽出すると529枚で、前処理①②を経由すると24枚にまで絞ることができました。
↓
しかもちゃんとメンバー一覧シーンも入ってそう。
3.画像データから自分の名前を検出
メンバー一覧シーンの抽出もできたので、いよいよAmazon Rekognitionにぶん投げてみます。
試しにAWSの管理コンソールからAmazon Rekognitionを開いてデモページから実行してみます。
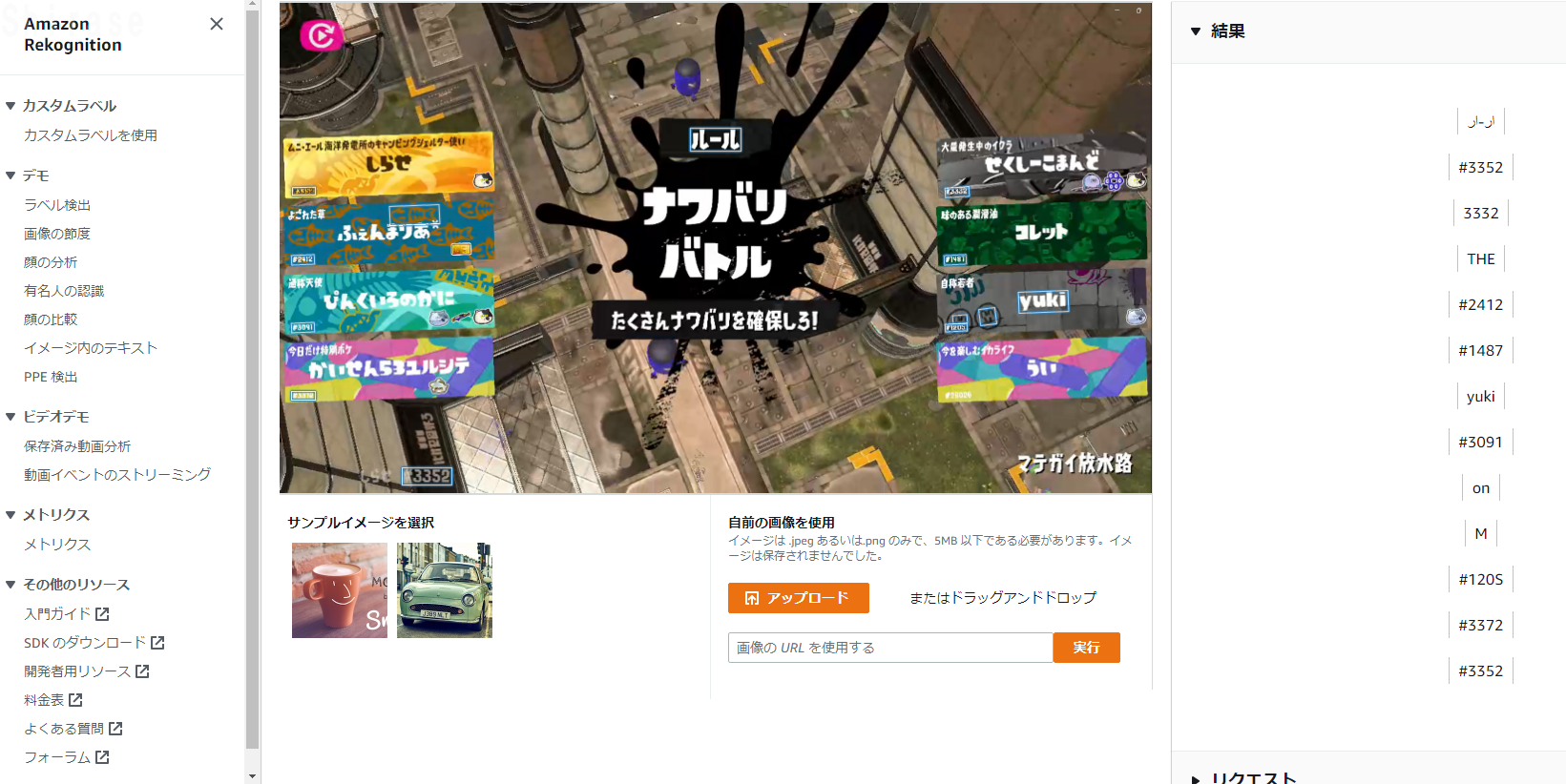
うーん。
名前が全く引っ掛かりませんね。
と、その前にAmazon Rekognitionは日本語対応していないことを失念してました。。
ニックネームは無理そう。
でもIDだけは何とか抽出できてるかも?だけど背景色が明るいとダメだな。
道筋は見えたのでAWSのPython用のSDKである「Boto3」を使ってAmazon Rekognitionを叩いてみます。
AWS管理コンソールでIAMでアカウントを作って、権限に「AmazonRekognitionReadOnlyAccess」を読み取りだけ付与します。
権限は最小限で行けますね。
そしてpythonスクリプトで「client.detect_text」を実行すると、、、
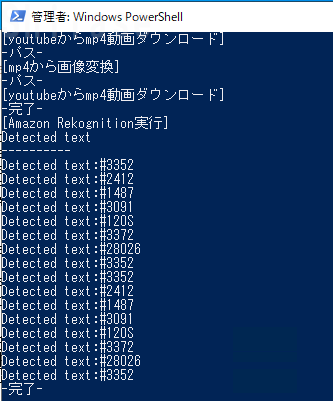
おおおおおおおおおおおお。
if文で「#」が含まれるテキストだけをフィルタしたらIDだけはちゃんと取れた。
※PowerShellで結果をユニークにしています。
でも所々5桁があるぞw
そしてやっぱりスプラフォントダメかぁ。
まとめ
いろいろやって気づいたことが2点あります。
1点目。
「Amazon Rekognitionすごい。」
今回はテキスト検出しかつかってませんが、ちゃんと文字を識別できている。
日本語に対応していないのは惜しいけど数字や英字はちゃんと判別できている。
これはもっと活用していきたいサービスですね。
2点目。
「実用性ねぇな」
スプラトゥーン3で導入されたネームプレートの番号。
これって4桁しかないんですよね。
スプラ人口に対して桁数少なすぎねぇか?!とは疑問に思っていたのですが。
調べてみるとやっぱり重複ありなんですね。
しかも名前変更で容易に変わるそうです。
【スプラトゥーン3】ネームプレートの番号の意味は?規則性はある? | 話のネタ - neta7.com
https://neta7.com/15073.html
IDで抜き出したところで自分のIDかどうか判別できない。。
350万人?のスプラ人口だと仮定すると9,000通りのIDで、、、約388人は同じIDがいるぞw
ということで実用性も無いのでこのチャレンジは失敗に終わりました。
最後に今回テストした結果の費用です。

「Amazon Rekognition APN1-Group2-ImagesProcessed」がサービス利用に載ってますが無料枠なので0円です。
また何かいい使い方を思いついたら使ってみます。
以上
おつかれさまでした。