

 しらせ(HN)
しらせ(HN)





前回:【第3回】社内インフラエンジニアのために(企画~リリース③)
お疲れ様です。
しらせです。
『社内インフラエンジニアのために』
第4回目となる今回は「安定化」についてです。
個人的にテレビゲームが好きということもあり、以前はよく配信者のためのツールを作っていました。
仕事の傍ら空き時間で作ったツールはアップデートができないことも多く、利用者に十分満足できる結果を残せなかったこともありました。
インフラも同じで、構築してリリースした後のケアがめちゃくちゃ重要です。
意図した使われ方をしているか?リソースは足りているか?運用は回っているか?
リリースしたその時から陳腐化は始まります。
ITILに「継続的サービス改善」という定義もありますので合わせて参考にしてみると良いと思います。
もくじ
ライフサイクルとロードマップの作成
「ライフサイクル」という言葉をWikipediaで引くと「設計寿命または設計耐用期間等の観念」のように記載されています。
機器には保守サポートが受けられる期間が指定されていたり、時期を待たずしても酷使されることでまともに使えなくなってしまうこともあります。
そうならないために、あらかじめ機器の耐用年数を想定して次回のタイミングに備えることが重要です。
そして、ライフサイクルの間にどんなことをやっていくかをまとめたものが「ロードマップ」です。
基本的には耐用年数や使用年数をベースにしてどんな施策を打っていくかを年表形式にまとめるだけでも良いと思います。
もちろん、機器だけでなく耐用年数の縛りのないクラウドサービスを利用する場合でも同じです。
クラウドサービスは、使った分だけ料金を支払うことで安定してサービスの提供を受けることが可能です。
技術革新の激しい現代において5年10年というスパンで見たときに、導入したシステムが会社にフィットし続けるということも多くないと思います。
どのような期間で見直しを掛けていくのか、どんな状況になったらシステムを停止してクローズするのか判断をするポイントをあらかじめ検討しておきます。
例
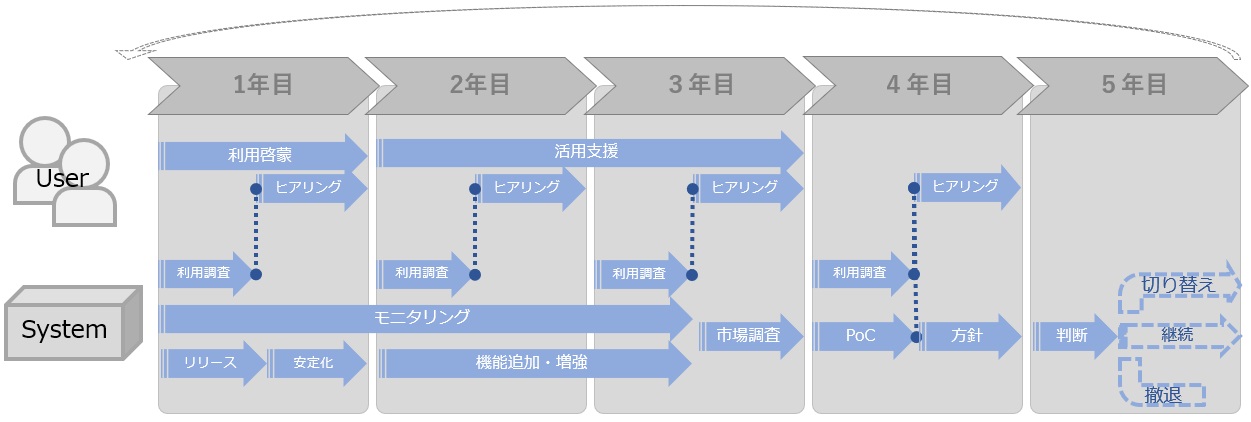
モニタリング
「リソース状況は24時間監視しているしアラートも来るから大丈夫」
そう思っていませんか?
インフラを長く安定運用していくためのカギは中長期的なモニタリングであると言っても過言ではありません。
ITを活用した業務の変化や従業員数の増減はインフラの変更よりも早いスピードで変わっていきます。
ネットワークファイアウォールではNAT(NAPT,PAT)のセッション上限に1IPアドレスあたり65,535という制限があります。
ストレージは確保している容量以上に保存はできませんし、CPUやメモリリソースは上限に達すると動作に影響が出ることがあります。
少人数で利用するNASのようなものであれば、家電量販店で裸族のHDDなんかを買ってくれば済むかもしれません。
これが数千人、数万人の規模で利用する大規模システムだったらどうでしょうか?
TB、PB級のストレージをいきなり増やすなんでクラウドサービスでも無理です。
このように、将来を見越したモニタリングができていないと想定外の停止にもつながります。
そうならないためにも日々のリソース監視はもちろんのこと、毎週・毎月・毎四半期・毎年などで区切って、過去のある時点からリソースの利用状況がどれくらい増えたか(減ったか)をチェックすることで、今のシステムがいつ限界に達するかを見極めることができます。
リソースが枯渇する時期の見込みが立てば、増強(スケールアウト、スケールアップ)するタイミングもつかみやすくなります。
参考としてストレージを例に記載していますが、システムの特徴や利用のされ方を元にしてモニタリング対象となる項目を検討すると良いと思います。
<ストレージの例>
- セッション数、ユーザー数
- システム負荷(CPU、メモリ、ネットワーク)
- ディスク使用容量・空き容量
- ファイル組成(拡張子、ファイルサイズ)
- アクセス種別割合(読み、書き)
※そのほかIOPSやレイテンシ、転送量など利用シーンに応じていろいろあります。
例
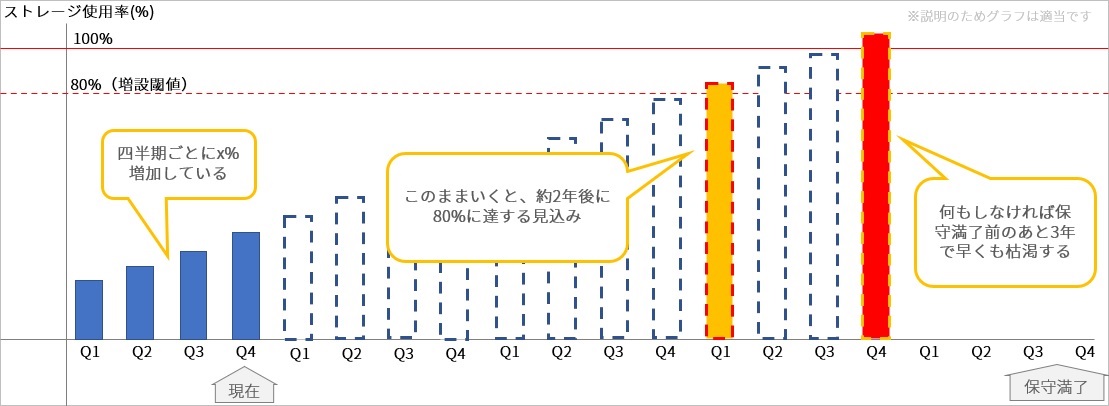
ヒアリング
ライフサイクルやロードマップの定義、モニタリングはすべて管理者視点での施策と言えます。
いくら管理者視点での施策が完璧でも実際の利用者からはどう見えているのか?という点も忘れてはいけません。
例えば、こんなことを言われることはないでしょうか。
「〇〇が使いづらいってxx部で噂になってるぞ?すぐに見直してくれ。」
これを言われた瞬間、これまでの管理者側の施策は無に帰します。
「〇〇使いづらいよねー」「xxを直してほしいよねー」
こんな話は管理者の耳に入るよりも先に利用者の輪で広がっていきます。
こうならないための有効な対策は、私が知る限り今のところ1つしかありません。
「利用者に直接聞く」
です。
もちろん、なんでもかんでもヒアリングをしていると従業員の貴重な業務時間を無駄に割くことになってしまいます。
内容や質問事項を十分整理検討したうえで、専用フォームを利用するなどして少しでも負荷を減らす工夫が求められます。
具体的なヒアリングの項目については触れませんが、個人的に気をつけたい点は以下です。
<入れるようにしている>
- 〇〇で満足に業務ができていますか? ←今のシステムで充足できているか?
- 〇〇で困っていることは何ですか? ←今のシステムがあることで課題になっていることはないか?
- どのような業務で利用していますか? ←企画時の要件通りに使われているか?
- 〇〇機能や〇〇機能は使えていますか? ←提供している機能がちゃんと使えているか?
- 用語〇〇、用語〇〇、を知っていますか? ←マニュアルの意味やルールが理解できているか?
<入れないようにしている>
- ほしい機能は何ですか? ←アイデア出しという点ではよいが、個別最適化に陥らないようにしたい。
- 〇〇をどうしてほしいですか? ←どうするかは管理者で考えること。
最近では顧客満足度調査やNPSなどのスコアリングも人気ですね。
ロードマップに沿って頻繁になりすぎない程度で実施できる良いと思います。
質問内容が全従業員に分かるように平易な言葉を選んでエンジニア要素を排除する心がけも大事です。
参考)
ネット・プロモーター・スコア - Wikipedia
今回はリリース後の安定化に関する内容でした。
次回はこれらの内容を元にした「見直し」に進みます。
以上
お疲れさまでした。