

 しらせ(HN)
しらせ(HN)





お疲れ様です。
しらせです。
8月に発生したAWSの障害を見ていてふと思ったことをちゃんと書きます。
もくじ
AWSで起きた障害
2019年8月23日の昼過ぎから変な胸騒ぎがしてTwitterを開いてみるとAWSで大規模な障害が発生していました。
東京リージョンの特定のAZでEC2インスタンスが落ちたような話も聞きました。
このブログも「ap-northeast-1a」AZのシングルインスタンスで動いていたにも関わらず、幸いにもEC2インスタンス自体もインスタンスの管理もできる状態でした。
こんなブログが一つ落ちたところで影響なんて無いに等しいですが、一方でゲームやECサイトや決済など生活に身近なサービスにも広く影響が出たことは記憶に新しいですよね。
※参考
◆東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
https://aws.amazon.com/jp/message/56489/
SLA(サービスレベルアグリーメント)
長くインフラエンジニアをやっていると、リージョンがどうとかマルチAZならどうとか、大いに気になるところではあります。
が、一方で私がちょっと気になったのがSaaSでよく謳われている「99.99%」などのSLA(サービスレベルアグリーメント)です。
EC2の場合SLAのページでは、99.0%未満で30%返金、99.9~99.0%の間で10%返金となっています。
※参考
10月10日現在、AWSのSLAページがメンテナンス中でヒストリーしか見れませんでした。
◆Prior Version(s) of Amazon EC2 Service Level Agreement - Not Currently In Effect
https://aws.amazon.com/jp/ec2/sla/historical/
止まること前提
クラウドサービスを選ぶ際に必ず9がいくつも並んだSLAを仕様説明ページで見かけると思います。
これが99.9%なのか、99.99%なのか、または99.999%なのかで、料金も違えば調達時に気にしている人もいるかと思います。
<年間の許容停止時間>
99.9% = 約8時間45分
99.99% = 約52分
99.999% = 約5分
一方でこのSLA、当たり前ですが定めた稼働時間に満たなかった場合は保証しますよ、というサービス提供側が提示した契約における条件みたいな意味合いでしかないんですよね。
「絶対にこの数値を下回らないように提供できます!」と謳っていれば話は別ですが、ほとんどの場合はSLAを下回った場合は返金なりの措置になりますよね。
つまり「止まる」こと自体を避けては通れないんですよね。
99.999999999%のクラウドサービスを契約しても止まるときは止まります。
熱や衝撃、ホコリや宇宙線にも強く、ネットワークも電源も多重化された完璧なサーバーであっても止まります。
データセンタの作業員が転んで、持っていた機械をラックに激しくぶつけて、運悪くコアスイッチを破損するかもしれません。
猫が侵入してケーブルを齧って使えなくしてしまうかもしれません。
見方を変えた可用性の考え方
どんなシステムでも稼働率を計算することはあると思います。
稼働率というよりも可動率(べきどうりつ)というほうが正しいのかもしれません。
一方で、冗長化されたシステムがどれほど障害に強いのか・可用性があると言えるのかを客観的にわかるような指標が欲しいなぁと思うわけです。
そこで例えば構成する機器1つ1つの信頼性の数値にとらわれずに、システムを構成する機器が「止まっている」か「動いている」かの2つの状態で可用性を考えたらどうか?
つまり動いている状態は50%で、止まっている状態も50%。
どんなに信頼性の高いパーツを使っている機器でも状態は「動いている状態」or「止まっている状態」の2つ。
それ以外に状態は無いのです。
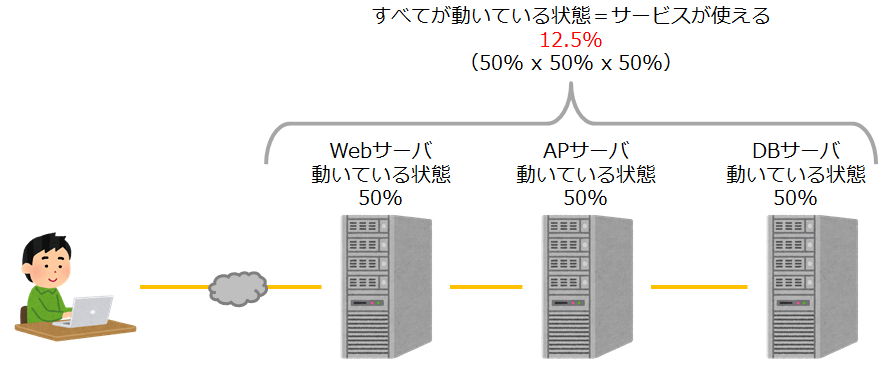
分かりやすいように簡単に例示をしてみます。
例1)
Webサーバ、APサーバ、BDサーバの3層システムそれぞれがシングルサーバで動いている場合の可用性。※つまり、すべてのサーバが動いていないと稼働しないシステム。
式:50%(動いている状態) * 50%(動いている状態) * 50%(動いている状態) = 12.5%
たまたまシステムが停止せずに12.5%の可用性の範囲でサービスを提供し続けている状態ですね。
どこか1台でも止まったらサービスも停止。怖いですね。
例2)
Webサーバ、APサーバ、BDサーバの3層システムそれぞれが3台で冗長化されたサーバ(最低1台でも稼働していればよい)で動いている場合の可用性。
式:87.5%(動いている状態) * 87.5%(動いている状態) * 87.5%(動いている状態) = 66.99%
3重のシステムでも、やはり直列になると数値は伸び悩みますね。。。

この理論で行くと、Web/AP/DBを1つのサーバに詰め込んでそれを冗長化させたら最強になります(笑)
5台で冗長化させて最低1台でも稼働していれば良いのであれば、96.875%の可用性を確保できますね!
まとめ
「サーバだけじゃなくて繋がっているネットワーク機器はどうするの?」
「電源の供給元である電力会社の冗長化はどうするの?」
「マルチリージョン・AZを考慮しなくていいの?」
など、いろんな観点があると思います。
定義の仕方は自由なので、何を考慮するかどのレイヤーで考えるかは各自に任せてしまおうと思います。
ただ伝えたかったのは、信頼性の指標に依存し過ぎないで動いている状態も止まっている状態も平等に存在するんだから、止まっている状態がある前提でシステムを作ろうね、ということです。
以上
お疲れさまでした。